
Login and password
Scraping data from web pages that requires login and password represents addional challange to stay authorized during the process. This is where requests.session() is extremely handy
Objective for this project was to collect data from web site with huge price list of prudcts for health. While some information is available without authorization, some important data is revealed only if you stay connected after login.
Python's request does all heavy job of connecting, loging and keep session alive while BeautifulSoup libraries helps to collect data for navigation and scraping.
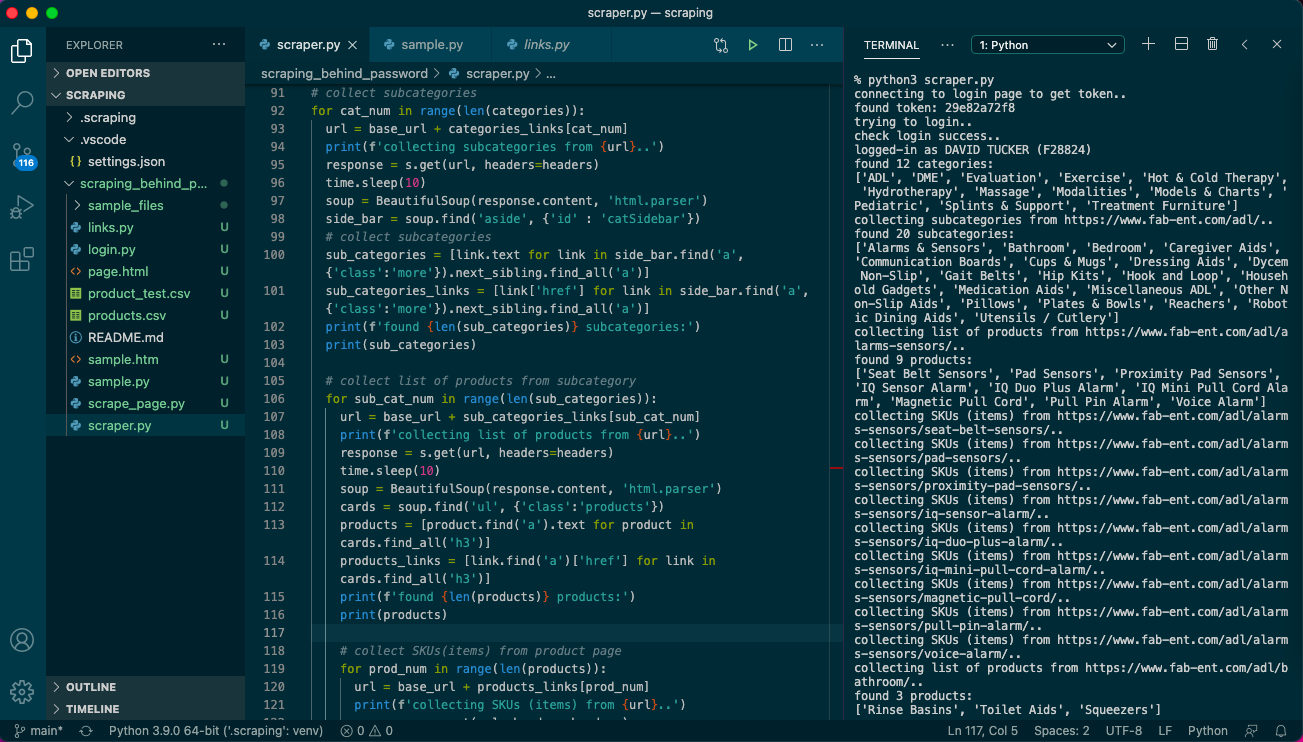
First step before loging is to get token value from hidden input of the form. Then you need to provide headers and cookies data for requests.session(). And do not forget to provide data with login and password.
Once you get connected, you need to collect navigation data from the site, and then follow the links to scrape data as needed from every page.
# import libraries
import requests
import time
from bs4 import BeautifulSoup
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Host': 'www.fab-ent.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.2 Safari/605.1.15',
'Accept-Language': 'en-gb',
'Referer': 'https://www.fab-ent.com/',
'Connection': 'keep-alive',
}
login_url = 'https://www.fab-ent.com/manage-account/'
# get token
response = requests.get(login_url, headers=headers)
print('connecting to login page to get token..')
time.sleep(10)
soup = BeautifulSoup(response.content, 'html.parser')
try:
token = soup.find('input', {'id':'_wpnonce'})['value']
print(f'found token: {token}')
except:
print('token not found.. exit')
exit()
# login
cookies = {
'PHPSESSID': '7pq0ohu5v4gvgf38p9umfirvot',
'_ga': 'GA1.2.923748210.1611468192',
'_gid': 'GA1.2.1435257517.1611468192',
'_fbp': 'fb.1.1611468192145.947029952',
'_mkto_trk': 'id:672-BAK-352&token:_mch-fab-ent.com-1611468193546-81679',
'wordpress_test_cookie': 'WP+Cookie+check',
'_gat': '1',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'Origin': 'https://www.fab-ent.com',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Referer': 'https://www.fab-ent.com/manage-account/',
'Accept-Language': 'en-US,en;q=0.9',
}
data = {
'username': 'foo',
'password': 'bar',
'_wpnonce': token,
'_wp_http_referer': '/manage-account/',
'login': 'Login'
}
# start the session
s = requests.Session()
# post to page to login
s.post('https://www.fab-ent.com/manage-account/', headers=headers, cookies=cookies, data=data)
print('trying to login..')
time.sleep(10)
# check if login succesfull
print('check login success..')
response = s.get('https://www.fab-ent.com/manage-account/', headers=headers)
time.sleep(10)
soup = BeautifulSoup(response.content, 'html.parser')
print(f"logged-in as {soup.find_all('a', {'class':'aboveHeaderLink'})[1].text}")
# collect categories
side_bar = soup.find('aside', {'id' : 'catSidebar'})
categories = [link.text for link in side_bar.find_all('a')]
categories_links = [link['href'] for link in side_bar.find_all('a')]
print(f'found {len(categories)} categories:')
print(categories)
base_url = 'https://www.fab-ent.com'
# collect subcategories
for cat_num in range(len(categories)):
url = base_url + categories_links[cat_num]
print(f'collecting subcategories from {url}..')
response = s.get(url, headers=headers)
time.sleep(10)
soup = BeautifulSoup(response.content, 'html.parser')
side_bar = soup.find('aside', {'id' : 'catSidebar'})
# collect subcategories
sub_categories = [link.text for link in side_bar.find('a', {'class':'more'}).next_sibling.find_all('a')]
sub_categories_links = [link['href'] for link in side_bar.find('a', {'class':'more'}).next_sibling.find_all('a')]
print(f'found {len(sub_categories)} subcategories:')
print(sub_categories)
# collect list of products from subcategory
for sub_cat_num in range(len(sub_categories)):
url = base_url + sub_categories_links[sub_cat_num]
print(f'collecting list of products from {url}..')
response = s.get(url, headers=headers)
time.sleep(10)
soup = BeautifulSoup(response.content, 'html.parser')
cards = soup.find('ul', {'class':'products'})
products = [product.find('a').text for product in cards.find_all('h3')]
products_links = [link.find('a')['href'] for link in cards.find_all('h3')]
print(f'found {len(products)} products:')
print(products)
# collect SKUs(items) from product page
for prod_num in range(len(products)):
url = base_url + products_links[prod_num]
print(f'collecting SKUs (items) from {url}..')
response = s.get(url, headers=headers)
time.sleep(10)
soup = BeautifulSoup(response.content, 'html.parser')
# prepare list to store results
results = []
# collect table rows from page
table = soup.find('table').find_all('tr')
for row in range(len(table)):
# check if row is a header
if 'th' in [ tag.name for tag in table[row] ]:
continue
if len([tag.name for tag in table[row]]) > 3:
# prepare dict for item
item = {}
# collect data from cells in each row
item_row = table[row].find_all('td')
item['item_id'] = item_row[0].text
item['item_desc'] = item_row[1].text
item['item_price'] = item_row[2].text
# check if price2 exists (not exists if not logged-in)
try:
item['item_price2'] = item_row[3].text
except:
item['item_price2'] = ''
if len([tag.name for tag in table[row]]) < 4:
item['dimensions'] = ''
item['weight'] = ''
item['upc'] = ''
for tag in table[row].find_all('strong'):
if tag.text == 'Dimensions:':
item['dimensions'] = tag.next_sibling
if tag.text == 'Weight:':
item['weight'] = tag.next_sibling
if tag.text == 'UPC:':
item['upc'] = tag.next_sibling
# add item to list
results.append(item)
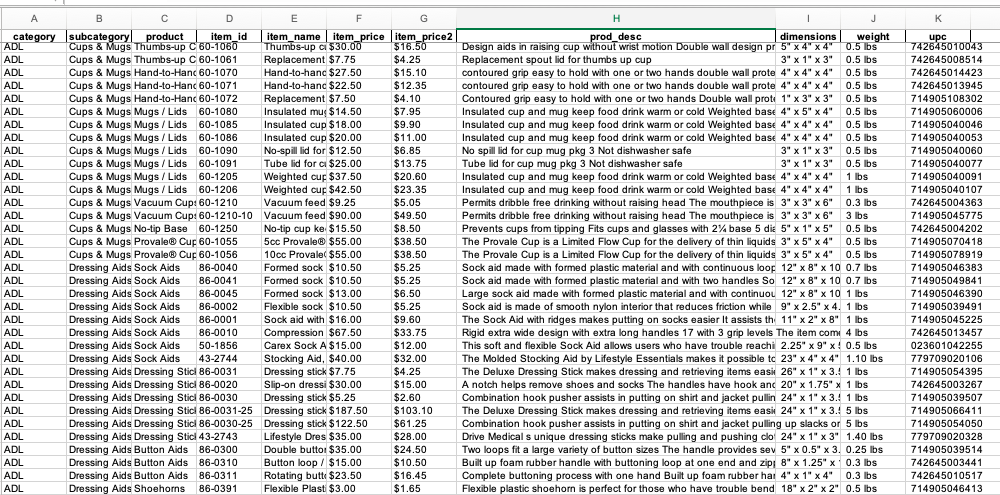
# save data to DataFrame
with open('product_test.csv', 'w') as file:
writer = csv.DictWriter(file, results[0].keys())
writer.writeheader()
writer.writerows(results)
Thank you for viewing my project. Any comment, suggestion, please adress to me by email bellow.